SPA の高速化のために CDN で配信する
とある SPA を高速化のために CDN(CloudFront)で配信するようにしました。この作業を通じて様々なノウハウを得たので書き残しておきたいと思います。 CDN での配信の目的は次の 3 つです。
- 高速化によるユーザー体験の改善
- ユーザー体験の改善による SEO 効果
- クローラーへの応答の高速化による SEO 効果
1 については CDN 化することで改善を目指します。
2 については、Google は一般ユーザーによる Chrome の利用データを検索ランクに利用しているので、高速化により一般ユーザーの体験が改善することで SEO 効果が期待できます。
https://www.suzukikenichi.com/blog/google-uses-crux-to-measure-page-speed/
ページの読み込み速度をモバイル検索のランキング指標に取り入れる Speed Update(スピード アップデート)を 7 月に控えています。
ページの読み込み速度を知る情報として Chrome User Experience Report(以下、CrUX)をたしかに使っているとのことでした。
3 についてはクローラーに対する応答速度です。クロール頻度に影響があると言われています。
https://spelldata.co.jp/blog/blog-2019-04-17.html
もしもあなたが確認したとき、その時間が 1000ms を超えているということは、ページの読込は 1 秒以上掛かっているということですから、それは本当にあなたのサーバは遅い部類に属しているという兆候です。 本来、私達がクローリングできるページ数を制限している一つの要因でしょう。
ダイナミックレンダリング
このシステムでは SEO のために prerender.io によるダイナミックレンダリングを利用しています。 ダイナミックレンダリングとは、本来ブラウザで行われるレンダリングをサーバー側で行ってその結果を返す仕組みで、JavaScript に対応していないクローラーに有効な手法です。 Googlebot は JavaScript に対応していますが完全ではないようで、ダイナミックレンダリングの効果が期待できます。半年後なのか 1 年後、3 年後なのか将来的には Googlebot を含むクローラーが JavaScript を完全に解釈してダイナミックレンダリングの必要がなくなると思われますが、現時点では効果があると考えています。 なお Google はクローキング(クローラーにユーザーと異なるコンテンツを返すこと)を禁止していて、その上でダイナミックレンダリングはクローキングではないとしています。
https://developers.google.com/search/docs/guides/dynamic-rendering
Googlebot は通常、ダイナミック レンダリングをクローキングとは見なしません。
移行前の構成
次の図は移行前の構成です。ブラウザからのアクセスには HTML 等の静的ファイルを返します。クローラーからのアクセスの場合には prerender.io のサーバーに問い合わせます。prerender.io は Headless Chrome でサイトをレンダリングし、その結果を返します。レンダリング結果はキャッシュされます。
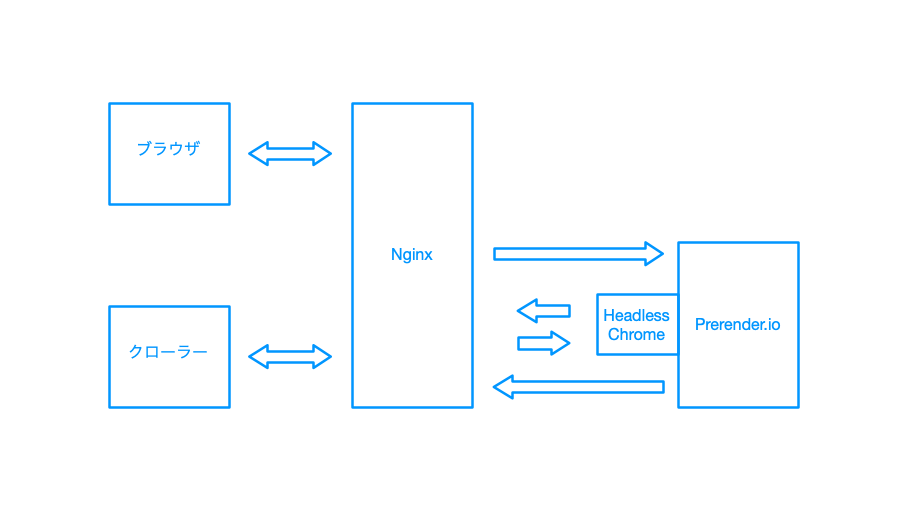
主要なクローラーである Googlebot は通常アメリカ国内からアクセスしてきます。この Nginx は日本にあったので、Googlebot (アメリカ) → Nginx (日本) → prerender.io (アメリカ) → Nginx (日本) → prerender.io (アメリカ) → Nginx (日本) → Googlebot (アメリカ) と何度も往復して相当時間がかかっていたはずです。
移行後の構成
次の図が移行後の構成です。見ての通り Nginx が CloudFront に変わっただけですが、Googlebot の場合のやりとりがすべてアメリカ国内で完結するようになりました。もちろんブラウザからのアクセスは CloudFront の適切なエッジサーバーにつながるため高速で処理されます。
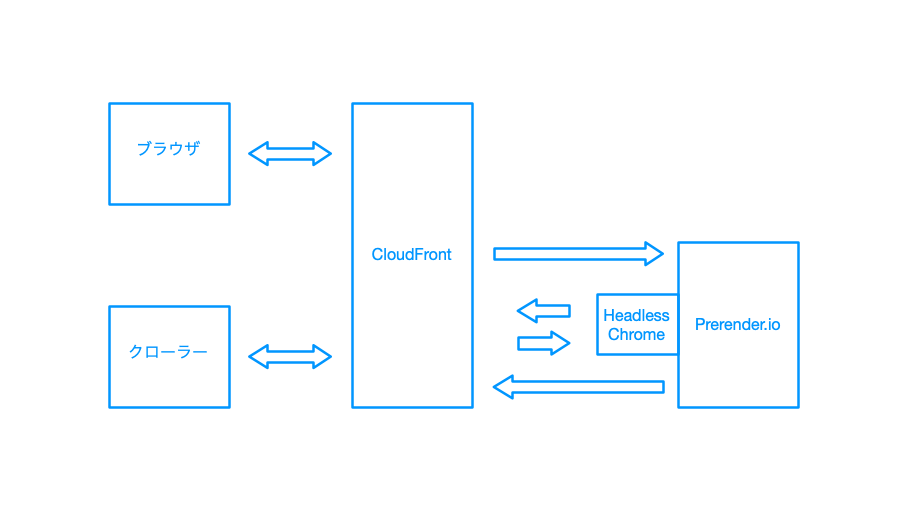
構成
S3 バケット
基本的に、HTML や CSS, JavaScript などの配信対象のファイルは S3 バケットに配備します。用途ごとに 3 つのバケットを用意しています。
webapp バケット
SPA 本体を入れます。ここでは webpack (create-react-app) でビルドする React アプリを使っています。リリース時には既存ファイルを全部削除してnpm run buildでビルドされたディレクトリの中身をコピーし、必要に応じて Content-Type 等のメタデータを付けています。このデプロイ処理のために簡単なツールを作成しました。
CSS アーカイブバケット
アプリの新しいバージョンをデプロイした後でも prerender.io でしばらくの間キャッシュが有効であり、キャッシュされた HTML からの古いバージョンの CSS への要求にも答える必要があります。さもなければクローラーが適切にレンダリングできず、SEO に甚大な悪影響を生じてしまいます。そこで CSS 保存用バケットに過去の CSS 全てを保存しておいて、webapp バケットに CSS が見つからない場合に Lambda@Edge の origin-response のタイミングでアーカイブバケットを検索します。アプリのリリース時にアーカイブバケットへの CSS ファイル配備を行います。アーカイブバケットにはアクセスされる可能性のある過去にリリースしたすべての CSS を配備します。prerender.io のキャッシュ期間より前にリリースしたファイルは削除しても構いませんが、管理が面倒なので残しておきます。
補助バケット
アプリのリリースとは別のタイミングで生成、更新されるファイルを置くバケットです。たとえばこのシステムでは sitemap.xml をバッチ処理で生成しています。このようなファイルをアプリと別で管理するためにバケットを分けています。補助バケットへのアクセスは CloudFront のビヘイビアにより制御します。たとえば/sitemap.xmlを補助バケットにマップするルールを設定します。
API サーバー
CloudFront のビヘイビアで特定のパス (/api/*など)を API サーバーに転送します。
CloudFront はレスポンスにContent-Typeヘッダがある場合だけ圧縮をサポートしているため、API サーバーがレスポンスを生成しながら返す場合にはContent-Lengthヘッダを付けられないので、API サーバー側で圧縮しておきます。(API サーバーにAccept-Encodingを転送しておく必要があるでしょう)

Lambda@Edge
Lambda@Edge を使って CloudFront へのリクエストに応じた処理を行います。CloudFront のイベントに次のように処理を割り当てます。
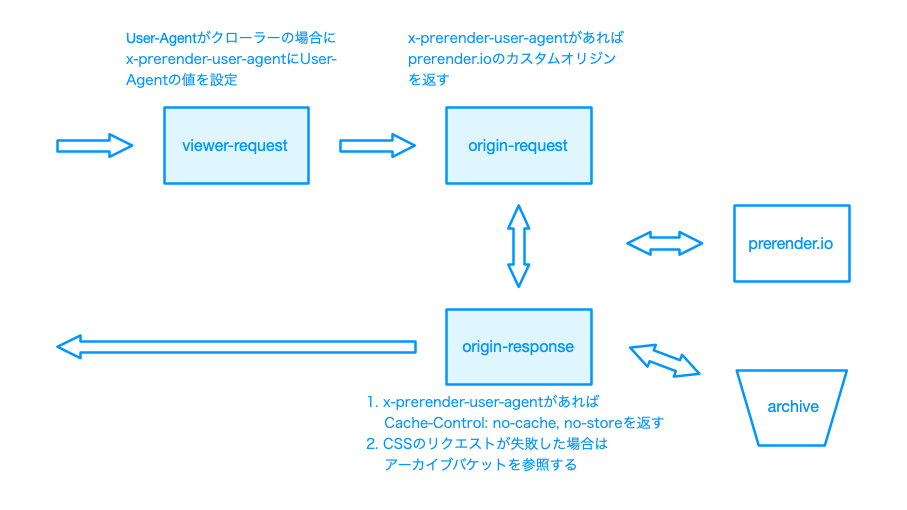
viewer-request
User-Agentヘッダを見てクローラーかどうかを判別する。クローラーの場合はx-prerender-user-agentヘッダにUser-Agentヘッダの値をそのまま入れておきます。CloudFront ではx-prerender-user-agentをキャッシュキーとして設定し、クローラーと一般のブラウザとでキャッシュを分けます。(クローラー向けのレスポンスは origin-response でキャッシュを回避しています)
origin-request
x-prerender-user-agentがあれば prerender.io に向けたカスタムオリジンを返します。これで CloudFront が prerender.io に問い合わせてくれます。
origin-response
Cache-Controlヘッダにno-cache, no-storeを設定してダイナミックレンダリングの結果のキャッシュを避けます。prerender.io 側でキャッシュがあることと、挙動をシンプルにするためにここではキャッシュしません。- CSS へのリクエストが失敗した場合にアーカイブバケットを参照します。CSS のアーカイブの項目参照
まとめ
この構成により CDN で配信して高速化することができました。ダイナミックレンダリングを使っている場合は prerender.io などのダイナミックレンダリング用サーバーへの転送、古い CSS の提供など考慮すべき事柄がいくつかありましたが、無事に稼動させることができました。